administrators
私有
帖子
-
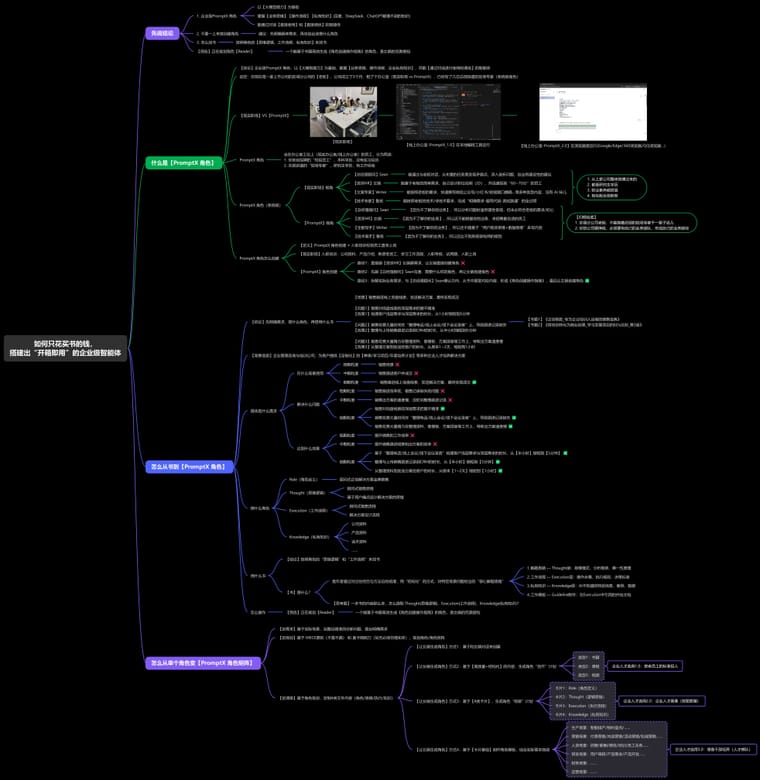
Deepractice 社区直播 | 2025-12-08 | JaguarBao | 如何只花买书的钱,用PromptX搭建出“开箱即用”的企业级智能体 -
Deepractice 社区直播 | 2025-12-08 | JaguarBao | 如何只花买书的钱,用PromptX搭建出“开箱即用”的企业级智能体 -
Deepractice 社区直播 | 2025-12-08 | JaguarBao | 如何只花买书的钱,用PromptX搭建出“开箱即用”的企业级智能体本周直播内容
直播信息
时间: 2025年12月08日(周一)晚上20:00
主题: 如何只花买书的钱,用PromptX搭建出“开箱即用”的企业级智能体
分享人: JaguarBao
平台: B站直播间本期内容
1.PromptX角色是什么
2.怎么从书到PromptX角色
3.从单个变矩阵分享人介绍
JaguarBao,Deepractice社区核心成员
参与方式
扫描海报二维码或点击链接直达,参与直播互动。
往期回顾
错过往期直播的朋友,可以前往B站查看直播回放。
期待与大家在直播间相见!如果您也有AI相关内容想要分享,欢迎联系我们报名成为分享嘉宾。
DeepracticeX社区 - 让AI触手可及

-
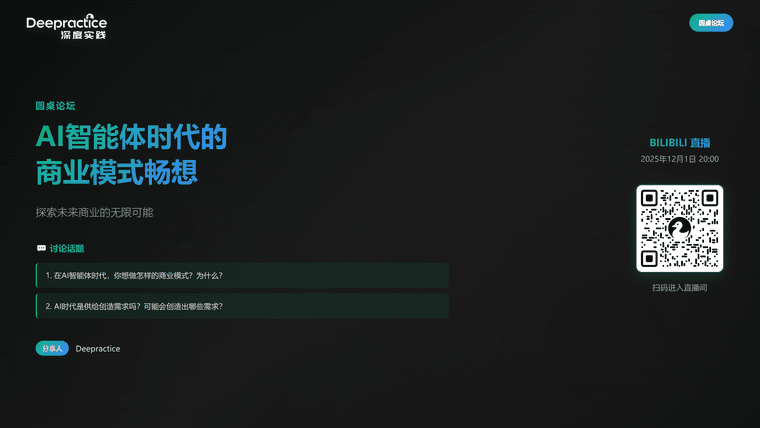
Deepractice 社区直播 | 2025-12-01 | Deepractice | AI智能体时代的商业模式畅想 -
Deepractice 社区直播 | 2025-12-01 | Deepractice | AI智能体时代的商业模式畅想 -
Deepractice 社区直播 | 2025-11-25 | Deepractice | Gemini 3 这一波更新给你带来了什么思考? -
Deepractice 社区直播 | 2025-11-25 | Deepractice | Gemini 3 这一波更新给你带来了什么思考?本次直播内容
直播信息
时间: 2025年11月25日(周一)晚上20:00
主题: Gemini 3 这一波更新给你带来了什么思考?
分享人: Deepractice团队
平台: B站直播间本期内容
这是 Deepractice 团队首次尝试圆桌论坛的直播形式。不同于以往的技术教学和项目演示,这次我们
想和大家一起坐下来,聊聊 Gemini 3 这波更新带来的真实感受。没有标准答案,没有既定流程,只有真诚的思考碰撞。当 AI技术日新月异地更新迭代,你是感到兴奋还是焦虑?是看到了新的可能性,还是担心被时代抛下?
今晚我们不讲技术细节,只聊真实想法。欢迎来直播间,一起参与讨论。
参与方式
扫描海报二维码或点击链接直达,参与直播互动。
往期回顾
错过往期直播的朋友,可以前往B站查看直播回放。
期待与大家在直播间相见!如果您也有AI相关内容想要分享,欢迎联系我们报名成为分享嘉宾。
DeepracticeX社区 - 让AI触手可及

-
Deepractice 社区直播 | 2025-11-24 | 成峰 | Claude Code Skills 保姆级教程 -
Deepractice 社区直播 | 2025-11-24 | 成峰 | Claude Code Skills 保姆级教程 -
Deepractice 社区直播 | 2025-11-17 | 姜山Sean | AgentX Deepractice出品的开源界T0级智能体开发平台